


DeepSeek Open Source Model: The $6M AI That’s Beating Silicon Valley’s Billion-Dollar Models
Is this a goodbye to ChatGPT? What happens now that this free open source model costs 30x less to operate on old hardware? A former hedge fund manager in Hangzhou has achieved what Silicon Valley thought impossible. Using just $6 million and a fraction of the computing resources available to U.S. tech giants, DeepSeek’s R1 model matches the performance of AI systems that cost billions to develop.
“When we first met him, he was this very nerdy guy with a terrible hairstyle talking about building a 10,000-chip cluster to train his own models. We didn’t take him seriously,” recalls one of Liang Wenfeng’s early business partners. Today, that vision has transformed into a technical achievement that’s shaking the foundations of AI development.
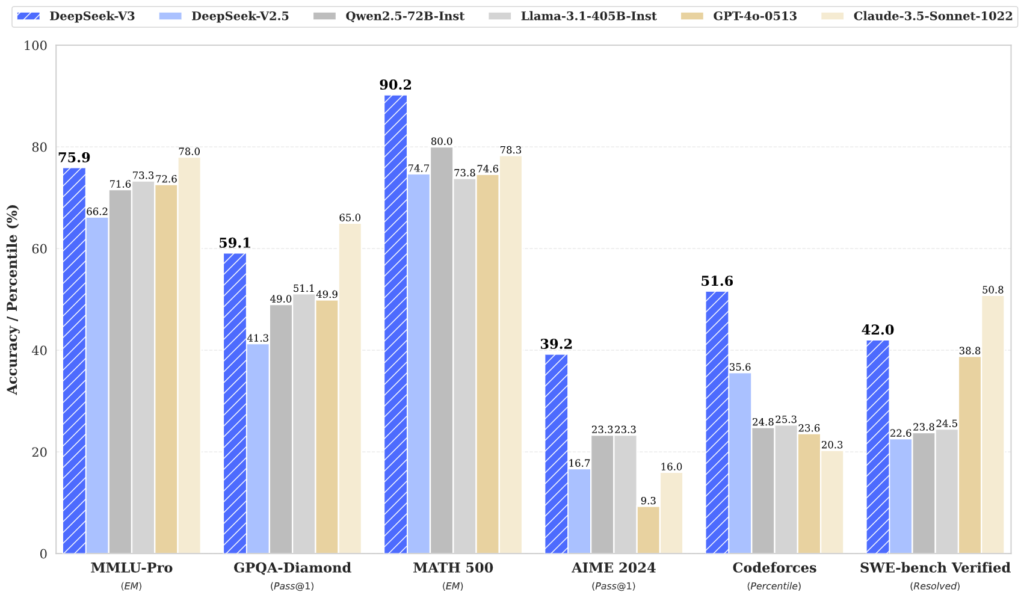
DeepSeek’s R1 isn’t just another language model. It excels in tasks requiring logical inference, mathematical reasoning, and real-time problem-solving – areas traditionally dominated by U.S. tech companies. More remarkably, it achieves this using just 2,048 Nvidia H800 chips, a constraint imposed by U.S. export restrictions.
The Innovation Breakthrough
What makes DeepSeek’s achievement extraordinary is its approach. While competitors pour billions into massive data centers, Liang’s team focused on efficiency. They developed methods to maximize the computing power of limited hardware – a skill honed during their days trading stocks at High-Flyer hedge fund.
“DeepSeek’s engineers know how to unlock the potential of these GPUs, even if they are not state of the art,” explains an AI researcher close to the company. This expertise has proven crucial as Chinese companies navigate U.S. chip export restrictions.
The Campus That’s Changing AI
DeepSeek’s offices feel more like a university campus than a tech company. Staffed primarily with PhDs from top Chinese universities like Peking and Tsinghua, the team has chosen a unique path. Unlike other Chinese tech companies, DeepSeek deliberately built its team without overseas talent, focusing instead on developing local expertise.
The Impact
The implications of DeepSeek’s breakthrough extend beyond technical achievement:
- Cost of Innovation: Demonstrated that groundbreaking AI development doesn’t require billion-dollar budgets
- Technical Barriers: Proved that chip restrictions can be overcome through optimization
- Talent Development: Showed that local expertise can match global standards
As Ritwik Gupta, AI policy researcher at UC Berkeley, notes: “There is no moat when it comes to AI capabilities. The second mover can get there cheaper and more quickly.” Here are more technical details on DeepSeek-V3 model.
The Road Ahead
While DeepSeek has shown impressive results with limited resources, challenges remain. The company’s computing capacity, while efficient, may face limitations as AI development accelerates. Yet, their achievement has already reshaped assumptions about AI development costs and capabilities.
The question isn’t whether DeepSeek can compete with Silicon Valley – they’ve already proven they can. The question is how this breakthrough will reshape the global AI landscape, where innovation efficiency might matter more than raw computing power.
Practical Applications and Competitive Edge
DeepSeek R1 challenges industry leaders with distinct advantages:
Mathematics and Problem-Solving
- Outperforms OpenAI’s o1 on American Invitational Mathematics Examination (AIME) benchmarks
- Achieves superior results on complex MATH dataset evaluations
- Delivers comparable performance to GPT-4 at fraction of computational cost
Code Development
- Open-source foundation enables unrestricted customization unlike OpenAI’s closed systems
- Matches Claude and GPT-4’s coding capabilities with faster execution
- Provides complete code ownership without API dependencies
Cost and Deployment Advantages
- $6M development cost vs billions for competitors
- No usage fees or API costs
- Full control over deployment and customization
- Smaller, distilled models for efficient operation
Technical Innovation
- Pure reinforcement learning approach sets new efficiency standards
- 671B parameters with only 37B activated per token
- Achieves top-tier performance using 95% less computing resources than competitors
Business Implementation
- Deploy on-premises without data sharing concerns
- Customize for specific industry needs
- Scale without usage restrictions or cost barriers
- Integrate with existing systems without vendor lock-in
This combination of performance, efficiency, and openness offers organizations an alternative to expensive proprietary solutions from OpenAI, Anthropic, and Google. The Wall Street Journal’s testing confirmed R1’s capabilities match or exceed established leaders in many tasks.
The big question is: Do we trust it?